МАТЕМАТИ́ЧЕСКАЯ СТАТИ́СТИКА
-

Рубрика: Математика
-

-

Скопировать библиографическую ссылку:
МАТЕМАТИ́ЧЕСКАЯ СТАТИ́СТИКА, раздел математики, посвящённый математич. методам систематизации, обработки и использования статистич. данных для науч. и практич. выводов.
Предмет и метод математической статистики
Под статистич. данными обычно понимают числовую информацию, извлекаемую из результатов выборочных обследований, результаты серии неточных измерений и вообще любую систему количественных данных.
Метод исследования, опирающийся на рассмотрение статистич. данных о тех или иных совокупностях объектов, называется статистическим. Статистич. метод используется во мн. областях знания. Однако черты статистич. метода в применении к объектам разл. природы столь разнообразны, что было бы бессмысленно объединять, напр., социально-экономич. статистику, звёздную статистику и т. п. в одну науку.
Общие черты статистич. метода в разл. областях знания сводятся к подсчёту числа объектов, входящих в те или иные группы, рассмотрению распределения количественных признаков, применению выборочного метода (в случаях, когда детальное исследование всех объектов обширной совокупности затруднительно), использованию вероятностей теории при оценке достаточности числа наблюдений для тех или иных выводов и при оценке точности получаемых результатов. Эта формальная математич. сторона статистич. методов исследования, не связанная со спецификой природы изучаемых объектов, и составляет предмет математич. статистики.
Связь математической статистики с теорией вероятностей
Связь М. с. с теорией вероятностей имеет в разных случаях разл. характер. Теория вероятностей изучает не любые явления, а явления случайные и именно «вероятностно случайные», т. е. такие, для которых имеет смысл говорить о соответствующих им распределениях вероятностей. Тем не менее теория вероятностей играет определённую роль и при статистич. изучении массовых явлений любой природы, которые могут не относиться к категории вероятностно случайных. Это осуществляется через основанные на теории вероятностей теорию выборочного метода и теорию ошибок измерений (см. Ошибок теория). В этих случаях вероятностным закономерностям подчинены не сами изучаемые явления, а приёмы их исследования.
При статистич. исследовании вероятностных явлений в полной мере находят применение такие основанные на теории вероятностей разделы М. с., как теория проверки статистич. гипотез, теория статистич. оценки распределений вероятностей или параметров этих распределений. При использовании этих разделов М. с. требуется, чтобы сами изучаемые явления подчинялись достаточно определённым вероятностным закономерностям. Напр., статистич. изучение режима турбулентных водных потоков или флуктуаций в радиоприёмных устройствах производится на основе теории стационарных случайных процессов. Однако применение той же теории к анализу случайных процессов в экономике может привести к грубым ошибкам ввиду того, что входящее в определение стационарного процесса предположение о наличии сохраняющихся в течение длительного времени неизменных распределений вероятностей в этом случае, как правило, неприемлемо.
Вероятностные закономерности проявляются в статистич. данных в силу больших чисел закона (напр., частоты событий близки к их вероятностям, а средние значения – к математич. ожиданиям).
Простейшие приёмы статистического описания
Изучаемая совокупность из $n$ объектов может по к.-л. признаку $A$ разбиваться на классы $A_1, A_2, ..., A_r$. Соответствующее этому разбиению статистич. распределение задаётся при помощи указания численностей $n_1, n_2, ..., n_r$ отд. классов, где $\sum_{i=1}^{r} n_i = n$. Вместо численностей часто указывают соответствующие относит. частоты $h_i=n_i/n, i=1, 2, ..., r$, удовлетворяющие соотношению $\sum_{i=1}^{r} h_i = 1$.
Если изучению подлежит некоторый количественный признак, то его статистич. распределение в совокупности из $n$ объектов можно задать, перечислив непосредственно наблюдённые значения признака $x_1, x_2, ..., x_n$. Однако при больших $n$ такой способ громоздок и в то же время не выявляет существенных свойств распределения. При больших $n$ на практике обычно не перечисляют наблюдённые значения признака $x_1,x_2,...,x_n$, а исходят лишь из численностей классов, получающихся при группировке наблюдённых значений по надлежаще выбранным интервалам.
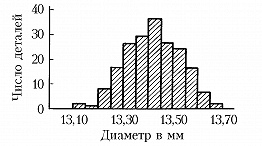
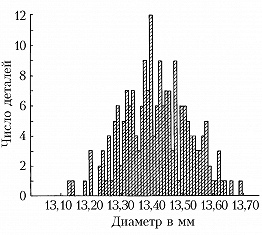
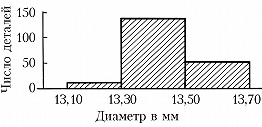
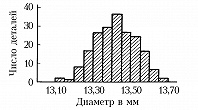
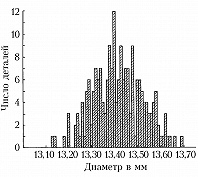
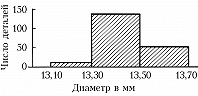
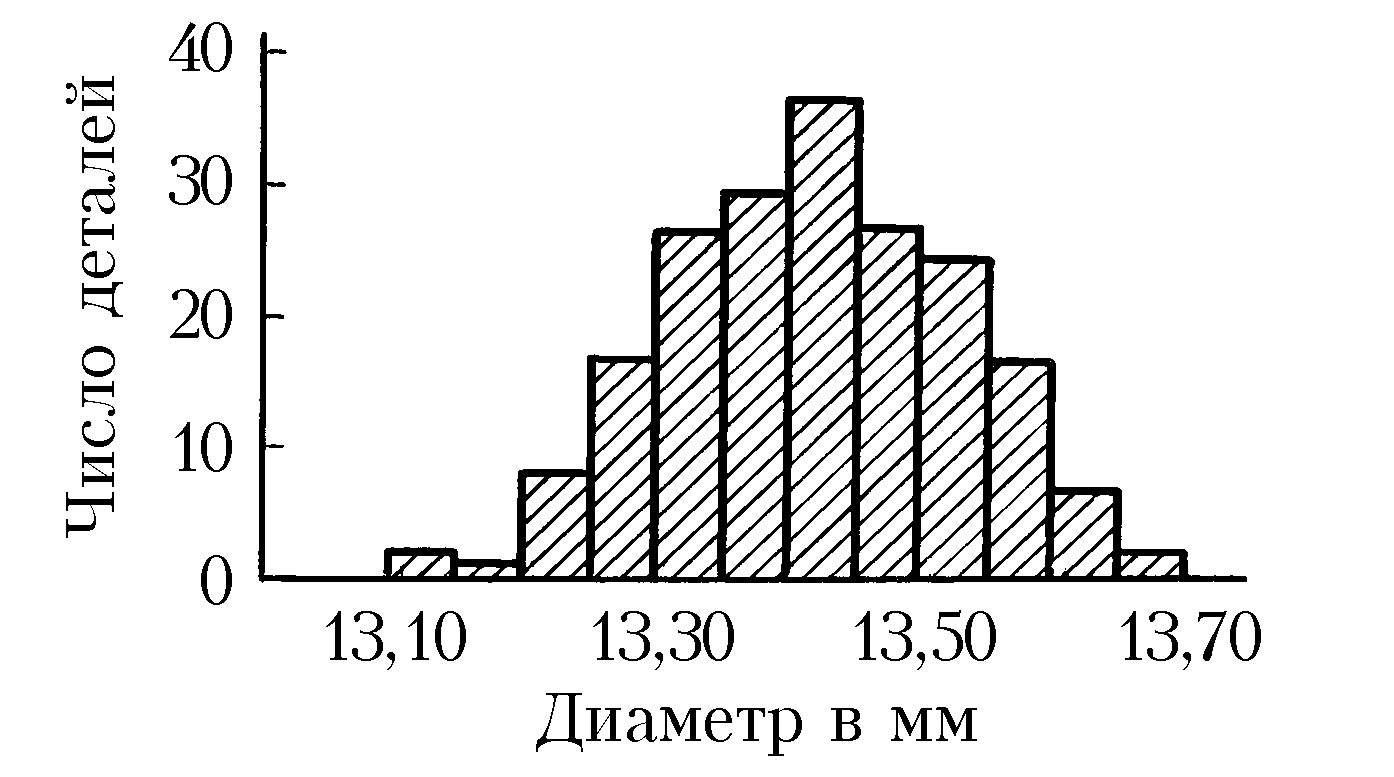
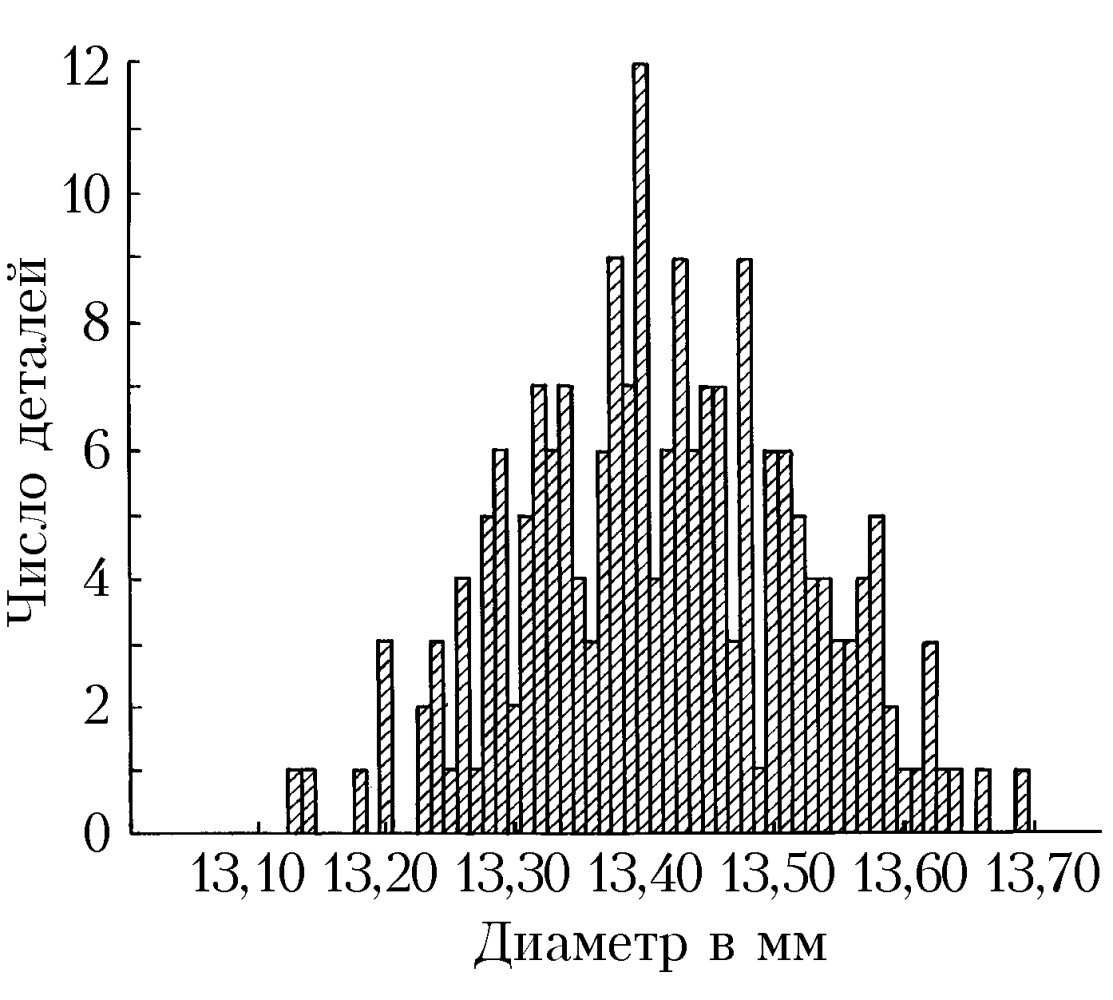
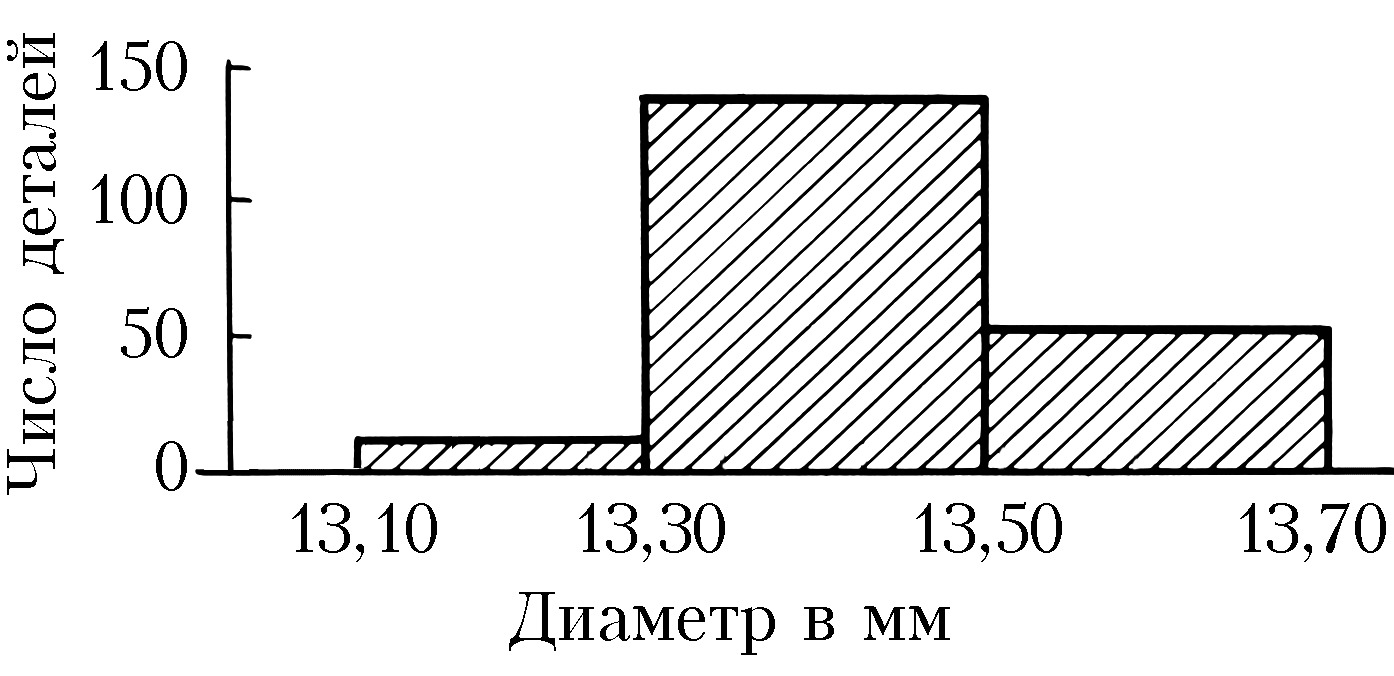
Обычно группировка по 10–20 интервалам, в каждый из которых попадает не более 15–20% наблюдённых значений признака, оказывается достаточной для довольно полного выявления всех существенных свойств распределения и надёжного вычисления по групповым численностям осн. характеристик распределения. По таким группированным данным составляется гистограмма, дающая представление о распределении признака. Гистограмма, составленная на основе группировки с малыми интервалами, обычно имеет нерегулярный вид и не отражает существенных свойств распределения. С др. стороны, группировка по слишком крупным интервалам может привести к потере ясного представления о характере распределения и к грубым ошибкам при вычислении среднего и др. характеристик распределения. В качестве примера на рис. 1 приведена гистограмма распределения диаметра некоторой детали (изучалась выборка из 200 деталей) при длине интервала группировки 0,05 мм, на рис. 2 – гистограмма того же распределения при интервале группировки 0,01 мм и на рис. 3 – гистограмма при интервале группировки 0,20 мм.
Простейшими сводными характеристиками распределения одного количественного признака являются выборочное среднее$$\overline{x}=\frac{1}{n}\sum_{i=1}^{n}x_i$$
и выборочное среднее квадратичное отклонение $D=S/\sqrt{n}$ или выборочная дисперсия $D^2=S^2/n$, где $$S^2=\sum_{i=1}^{n} (x_i-\overline{x})^2.$$
При вычислении $\overline{x}$, $S^2$ и $D$ по группированным данным пользуются формулами $$\overline{x}=\frac{1}{n}\sum_{k=1}^{r}n_ka_k=\sum_{k=1}^{r}h_ka_k,$$
$$S^2=\sum_{k=1}^{r}n_k(a_k-\overline{x})^2 = \sum_{k=1}^{r}n_ka_k^2-n\overline{x}^2$$
или $$D^2=\sum_{i=1}^{r}h_ka_k^2-\overline{x}^2 $$
где $r$ – число интервалов группировки, $a_k$ – их середины. Если материал сгруппирован по слишком крупным интервалам, то такой подсчёт даёт грубые результаты и иногда в таких случаях вводят спец. поправки на группировку.
Связь статистических распределений с вероятностными. Оценка параметров. Проверка статистических гипотез
Выше были изложены некоторые простейшие приёмы статистич. описания, которое является довольно обширной дисциплиной с хорошо разработанной системой понятий и техникой вычислений. Приёмы статистич. описания интересны, однако не сами по себе, а как средство для получения из статистич. материала выводов о закономерностях, которым подчиняются изучаемые явления, и о причинах, приводящих в каждом отд. случае к тем или иным статистич. распределениям.
Напр., данные, по которым получены гистограммы на рис. 1, 2, 3, были собраны с целью установления точности изготовления деталей, расчётный диаметр которых равен 13,40 мм, при нормальном ходе производства. Простейшим допущением, которое может быть в этом случае обосновано некоторыми теоретич. соображениями, связанными с центральной предельной теоремой, является предположение, что диаметры отд. деталей можно рассматривать как реализации случайной величины $X$, имеющей нормальное распределение вероятностей
$$ \mathbf{P} \{ X < x \}=\frac{1}{\sqrt{2\pi\sigma }}\int_{-\infty }^{x}e^{-(t-a)^2/(2\sigma )^2}dt.\tag{*}$$
Если это допущение верно, то параметры $a$ и $σ^2$ – среднее и дисперсию вероятностного распределения можно с достаточной точностью оценить по соответствующим характеристикам статистич. распределения (т. к. число наблюдений $n$ = 200 в этом случае достаточно велико), взяв в качестве $a$ величину $\overline{x}$ и в качестве $σ^2$ – величину $D^2$. Однако в качестве оценки для теоретич. дисперсии $σ^2$ предпочитают не статистич. дисперсию $D^2=S^2/n$, а несмещённую оценку
$$s^2=S^2/(n-1).$$
Дальнейшие сведения об оценке параметров теоретич. распределений вероятностей см. в статьях Статистическая оценка, Доверительный интервал.
Уже упоминалось, что предположение о том, что результаты наблюдений можно рассматривать как реализации случайной величины $X$, подчинённой тому или иному распределению, напр. нормальному распределению ( * ), иногда можно обосновать теоретич. соображениями. Однако на практике часто возникает задача о проверке гипотезы о том, что случайная величина $X$ имеет заданное распределение. Подробнее об этом см. в ст. Статистических гипотез проверка.
Все основанные на теории вероятностей правила статистич. оценки параметров и проверки гипотез действуют лишь с определённым значимости уровнем $ω<1$, т. е. могут приводить к ошибочным результатам с вероятностью $α=1-ω$. Напр., если предположить, что случайная величина $X$ имеет нормальное распределение с известной теоретич. дисперсией $σ^2$, и проводить оценку $a$ по $\overline{x}$ по правилу $$\overline{x}-\frac{k\sigma }{\sqrt{n}} < a < \overline{x} + \frac{k\sigma }{\sqrt{n}},$$
то вероятность ошибки, т. е. вероятность того, что указанное неравенство не выполнено, будет равна числу $α$, связанному с числом $k$ соотношением $$\alpha = \frac{2}{\sqrt{2\pi }}\int_{k}^{\infty }e^{-x^2/2}dx.$$
Вопрос о рациональном выборе уровня значимости в данных конкретных условиях (напр., при разработке правил статистич. контроля качества массовой продукции) является весьма существенным. При этом желанию применять правила лишь с высоким (близким к единице) уровнем значимости противостоит то обстоятельство, что при ограниченном числе наблюдений такие правила позволяют сделать лишь очень бедные выводы (напр., не дают возможности установить различие вероятностей двух событий даже при заметном различии частот этих событий).
Дальнейшие задачи математической статистики
В упоминавшихся выше задачах оценки параметров и проверки гипотез используется предположение, что число наблюдений, необходимых для достижения заданной точности выводов, определяют заранее (до проведения испытаний). Однако часто априорное определение числа наблюдений нецелесообразно, т. к., не фиксируя число опытов заранее, а определяя его в ходе эксперимента, можно уменьшить математич. ожидание числа необходимых наблюдений. Сначала это обстоятельство было подмечено на примере выбора одной из двух гипотез ($H_1$ или $H_2$) по последовательности независимых испытаний. Соответствующая процедура (впервые предложенная в связи с задачами приёмочного статистического контроля) состоит в следующем. На каждом шаге по результатам уже проведённых наблюдений решают а) провести следующее испытание, или б) прекратить испытания и принять гипотезу $H_1$, или в) прекратить испытания и принять гипотезу $H_2$. При надлежащем подборе количественных характеристик подобной процедуры можно добиться (при той же точности выводов) сокращения числа наблюдений в ср. почти вдвое по сравнению с процедурой, использующей выборки фиксиров. объёма (см. Последовательный анализ). Развитие методов последовательного анализа привело, с одной стороны, к изучению управляемых случайных процессов, с др. – к появлению общей теории статистических решений. Эта теория исходит из того, что результаты последовательно проводимых наблюдений служат основой принятия некоторых решений (промежуточных – продолжать испытания или нет, и окончательных – в случае прекращения испытаний). В задачах оценки параметров окончат. решения суть числа (значение оценок), в задачах проверки гипотез – принимаемые гипотезы. Цель теории – указать правила принятия решений, минимизирующих ср. риск или убыток (риск зависит и от вероятностных распределений результатов наблюдений, и от принимаемого окончат. решения, и от расходов на проведение испытаний).
Вопросы целесообразного распределения усилий при проведении статистич. анализа явлений рассматриваются в теории планирования эксперимента, ставшей важной частью совр. математич. статистики.
Наряду с развитием и уточнением общих понятий М. с. развиваются и её отд. разделы, такие как дисперсионный анализ, корреляционный анализ, многомерный статистический анализ, статистический анализ случайных процессов, регрессионный анализ, факторный анализ.
Историческая справка. Первые задачи М. с. появились в трудах Я. Бернулли, П. Лапласа и С. Пуассона. В России методы М. с. в применении к демографии и страховому делу развивал на основе теории вероятностей В. Я. Буняковский (1846). Решающее значение для дальнейшего развития М. с. имели работы представителей рос. школы теории вероятностей 2-й пол. 19 – нач. 20 вв. (П. Л. Чебышев, А. А. Марков, А. М. Ляпунов, С. Н. Бернштейн). Мн. вопросы теории статистич. оценок были по существу разработаны на основе теории ошибок и метода наименьших квадратов (К. Гаусс и А. А. Марков). Труды А. Кетле, Ф. Гальтона и К. Пирсона имели большое значение, но по уровню использования достижений теории вероятностей отставали от работ рос. школы. Пирсоном была широко развёрнута работа по составлению таблиц функций, необходимых для применения методов М. с. Она была продолжена во мн. науч. центрах (в СССР она велась Е. Е. Слуцким, Н. В. Смирновым, Л. Н. Большевым). В создании теории малых выборок, общей теории статистич. оценок, проверки гипотез (освобождённой от предположений о наличии априорных распределений), последовательного анализа значительна роль представителей англо-амер. школы [Стьюдент (псевд. У. Госсета), Р. Фишер, Э. Пирсон, Ю. Нейман, А. Вальд], деятельность которых началась в 1-й четв. 20 в. В СССР значит. результаты в области М. с. получены А. Н. Колмогоровым, В. И. Романовским, Слуцким, которому принадлежат важные работы по статистике стационарных рядов, Смирновым, заложившим основы теории непараметрич. методов М. с., Ю. В. Линником, обогатившим аналитич. аппарат М. с. новыми методами. На основе М. с. интенсивно разрабатываются статистич. методы исследования и контроля массового производства, статистич. методы в области физики, гидрологии, климатологии, звёздной астрономии, биологии, медицины и др.